
De eerste van drie blogs over spraaktechnologie, AI en voicebots. In gesprek met dr. Arjan van Hessen, Head of Imagination bij Telecats, sinds ’91 werkzaam op het gebied van Human Language Technology bij Lernout & Hauspie en de Universiteiten van Twente en Utrecht.
Wat is spraaktechnologie?
Spraaktechnologie is de verzameling van technieken die allemaal “iets” te maken hebben met het verwerken van de menselijke stem. Natuurlijk denk je dan direct aan boegbeelden zoals spraakherkenning en spraaksynthese, maar er is veel meer. Denk aan het proberen te bepalen van de emotie die er in een uiting zit, of denk aan de combinatie van wat en hoe iets gezegd werd dat gebruikt wordt voor de vroeg-detectie van brain disorders. Maar er is nog meer. Ook het bewerken van uitingen van het (menselijke) spraakkanaal hoort bij de noemer Spraaktechnologie. Denk hierbij aan het weghalen van ruis of gebrom, het helderder laten klinken van de spraak of versnellen/vertragen van de spraak zonder dat je dat hoort.
Omdat met name spraakherkenning door het gebruik van Deep Neural Networks (DNN) zo enorm veel beter is geworden, verschuift de interesse zich naar de volgende stap: niet meer wat wordt er gezegd, maar wat wordt er bedoeld. Omdat te kunnen is o.a. kennis van de wereld rondom zo’n spraakuiting nodig. Er wordt hier echter vooral met de resultaten van Automatic Speech Recognition (ASR) en andere tekstuele bronnen gewerkt waardoor dit strikt genomen meer taal- dan spraaktechnologie is. Maar door het toenemend belang van additionele taaltechnologie bij het verwerken van spraakdata, spreken we de laatste jaren eigenlijk vooral over Taal- en Spraaktechnologie.

Hoe volwassen is spraaktechnologie in 2020?
Sinds de ongeveer 2010 werd het gebruik van DNN’s in de verschillende onderdelen van ASR gebruikelijk. En het resultaat was behoorlijk indrukwekkend want overal waar daarvoor gebruik gemaakt werd, steef de performance. En niet een klein beetje, maar echt. Een van de gevolgen was de introductie van ASR op je eigen mobiele telefoon, iPad, laptop en gewone computer. Diensten zoals SIRI, Google Assistance en Alexa begonnen voor het Engels en breiden hun diensten snel uit naar andere populaire talen. Met de komst van dit soort geavanceerde diensten leek ook de weerstand van het grote publiek te verdwijnen. Doordat bovendien dezelfde technologie natuurlijk ook in de meeste Call Centres werd gebruikt, werd het publiek ook daar niet teleurgesteld in de algemene resultaten van spraakherkenning.
Op dit moment kunnen we stellen dat we boven de 90% correct kunnen herkennen mits…
- De audiokwaliteit optimaal is
- Er geen achtergrondruis is
- De spreker op een normale manier redelijk accentloos Nederlands spreekt en geen gebruik maakt van vreemde (jargon) woorden.
Waar gaat het nog fout?
Zeker bij telefonieservices zien we dikwijls dat het gesproken antwoord niet helemaal voldoet aan deze 3 eisen. Mensen bellen op straat (met veel achtergrondlawaai), spreken zonder precies te weten wat ze nu willen en gebruiken daarbij lang niet altijd iets dat lijkt op accentloos Nederlands. Bovendien is komt aanzienlijk deel van de gebruikers oorspronkelijk niet uit Nederland waardoor het gebruikte Nederlands suboptimaal is.
Aan de andere kant stellen veel mensen wel dezelfde soort vragen waardoor we met een redelijke dataverzameling fouten kunnen corrigeren. Wanneer we kijken naar de resultaten van de meeste telefonische diensten, dan kunnen we voorzichtig stellen dat we meer dan 90% van de gemaakte opnamen, correct afhandelen.
Hoe kan en wordt spraaktechnologie gebruikt in customer service?
Een belangrijk toepassingsveld van automatische spraakherkenning ligt in gesprekken die klanten en bedrijven en/of organisaties met elkaar voeren. Het leeuwendeel van deze gesprekken gebeurt via de telefoon hoewel ook er een duidelijk stijging is in het gebruik via andere devices zoals tablet of laptop. Moderne telefoons gebruiken allerlei algoritmes om ervoor te zorgen dat de kwaliteit van hun gesprekken zo goed mogelijk wordt. Toch is telefoonspraak meestal minder goed dan de bureauspraak en dat heeft tot gevolg dat de ASR-resultaten dat meestal ook zijn. Maar ondanks deze ietwat lagere kwaliteit van de spraakherkenning, worden ASR en Text To Speech (TTS) steeds massaler ingezet in klantgesprekken.
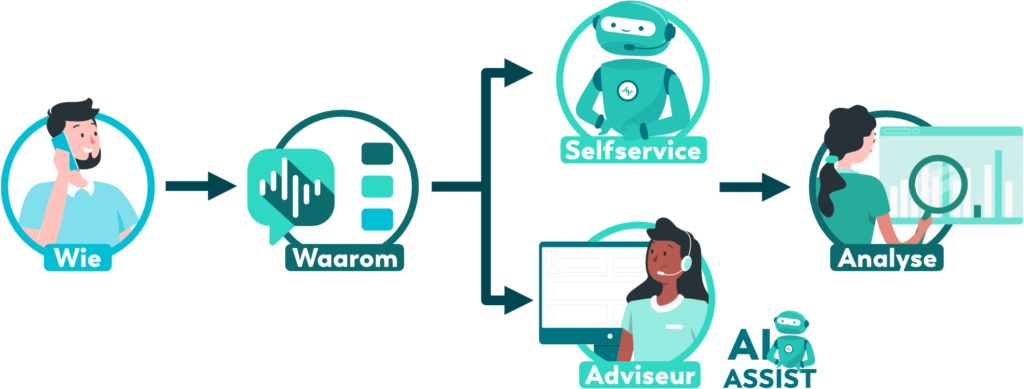
Bij een klantgesprek gaat het meestal om drie zaken: wie belt wanneer waarvoor. De eerste stap (wie er belt) kan redelijk eenvoudig worden opgelost door een aan de beller gekoppeld ID te vragen. Denk aan bv een postcode en huisnummer, een klantnummer of aan andere ID’s die een uniek resultaat leveren. Het tweede item is helemaal geen probleem omdat elk systeem de datum en het tijdstip logt en opslaat bij het gesprek.
Het derde item is lastiger. Natuurlijk kun je gewoon vragen waarom iemand naar een bepaald nummer belt, maar het interpreteren van het gegeven antwoord is minder makkelijk. Hier zijn twee verschillende methodes voor. De eerste is het laten beantwoorden van elke gesprek door menselijke experts, het opslaan van elk gegeven antwoord en het trainen van een Machine Learnings applicatie met de gegeven antwoorden. M.a.w. je hebt de ASR-resultaten, je hebt het door mensen gegeven “label” en gebruikt die combinatie om een ML-algoritme te trainen om het juiste label te plakken aan een nieuw gesprek. Dit werkt goed, maar is wel redelijk tijdintensief omdat bij elke nieuwe klant steeds weer een groot aantal gesprekken door menselijke experts beoordeeld moet worden.
Een tweede oplossing is het “begrijpen” van de herkenningsresultaten om daar vervolgens iets zinvols mee te doen. Denk bv aan een zinnetje als “ik wil, eh, graag een, eh, twee eigenlijk, twee rode stoelen bij jullie ophalen, eh kopen bedoel ik”. Bij het begrijpen van de zin, zou daar iets uit kunnen komen dat lijkt op “actie: kopen; doel: stoelen; bijzonderheden: kleur=rood; aantal:2”. Als dit zou lukken, dan kun je veel sneller nieuwe applicaties maken voor bv een boekverkoper, een meubelzaak of een autodealer, waarbij je ipv steeds weer opnieuw grote hoeveelheden spraak te moeten labelen, kunt volstaan met het bijsturen van de algemene applicatie. Maar… hier wordt hard aan gewerkt binnen de (academische) onderzoeksinstituten en voorlopig werkt het nog niet zo goed als de eerste methode.
Wat zijn de voordelen voor de klant?
Het zou een illusie zijn te veronderstellen dat mensen liever geen menselijk contact zouden willen hebben in de telefoongesprekken die ze met bedrijven/organisaties voeren. Alleen hoeft dat niet altijd. Kijken we naar de geschiedenis van het automatiseren van klantgesprekken, dan zien we eerst een hele tijd niks. Je belde, legde uit wie je was en waarom je belde en vervolgens kreeg je antwoord of werd je doorverbonden naar een volgend nummer waar alles weer overnieuw begon. Enerzijds was dit ergerlijk omdat je dikwijls twee of drie keer hetzelfde verhaal moest houden, anderzijds kon het lekker snel gaan wanneer de telefoniste direct begreep wat je wilde weten en daar ook het juiste antwoord op kon geven.
Met de komst van telefoons met drukknoppen kwam de mogelijkheid om een selectie te maken voor je met een menselijk iemand het gesprek ging voeren. Denk daarbij aan dialogen als “toets 1 als u iets wilt weten over de verkoop, toets 2 als u iets wilt weten over het bezorgmoment, toets 3 als…”. Bedrijven konden zo hun gesprekken efficiënter voeren, maar voor de klanten was het niet altijd een feest: zeker wanneer je niet begreep wat je hier nu precies gevraagd werd.
Met de komst van simpele vormen van spraakherkenning halverwege de jaren 90 werd meer mogelijk. Via slim geconstrueerde software konden mensen slot voor slot de gewenste antwoorden geven, maar konden ze dat ook in een keer direct doen. Een voorbeeld was het reserveren van een kamer in een hotel. Je moest dan antwoord geven op wanneer, hoe lang, hoeveel personen, specialiteiten zoals bv wel/niet een hond mee, kamer begane grond en meer. Wanneer je dan insprak “volgende week woensdag voor drie nachten” dan waren de eerste twee slots direct gevuld en kon je verder gaan met de resterende slots.
Maar de ontwikkelingen binnen de ASR gingen verder en werden, zeker na de komst van DNN’s rond 2010 snel veel beter. Tegenwoordig wordt de spraak “gewoon” herkend, en worden de sloten uit het herkende antwoord gehaald. Dus ook hier zien we die stap naar het gebruik van zowel Spraak als Taaltechnologie weer opduiken.
Het grote voordeel van deze toenemende automatisering van klantgesprekken, is dat mensen uiteindelijk altijd een gesprek met het bedrijf/organisatie kunnen voeren op tijdstippen die hen uitkomen. Bovendien worden ze sneller geholpen doordat er geen of nauwelijks meer wachtrijen zijn. Maar ook voor bedrijven is er een groot voordeel in het gebruik van geautomatiseerde dialogen. Ze kunnen makkelijker een plotselinge toename van gesprekken aan, ze krijgen veel gedetailleerdere managementinformatie, en het is op den duur een stuk goedkoper. Natuurlijk is het niet zo dat mensen er geheel tussenuit gehaald kunnen worden. ASR maakt fouten, mensen weten niet altijd precies de goede vraag te stellen en er zullen altijd gevallen zijn waar niet in voorzien werd bij het maken van het geautomatiseerde systeem. Maar dat is niet erg, want hiervoor zijn mensen vooralsnog een stuk beter geschikt dan machines.
Wat is de toekomst van spraak technologie?
De ontwikkelingen op het gebeid van spraaktechnologie focussen zich vooral op drie vlakken: herkenning en in toenemende mate op het begrijpen wat iemand zegt of bedoeld, spraaksynthese waarbij de natuurlijkheid van de door de computer gebezigde spraak niet of nauwelijks meer van die van een echt mens te onderscheiden is en het gebruik van emotie (zowel in het herkennen als in het gebruik van computerspraak).
Want hoewel de resultaten van ASR steeds beter worden, is het zeker niet zo dat alle herkenningsproblemen opgelost zijn. Sprekers met een zwaar accent, mensen die het Nederlands niet als moedertaal geleerd hebben, opnamen in de nabijheid van veel lawaai of onduidelijke formuleringen. Dit zij allemaal factoren die ervoor zorgen dat de herkenning van wat er gezegd (en bedoeld) werd, niet optimaal zijn.
Voor een deel weten we wat we eraan kunnen doen: betere akoestische modellen, bredere taalmodellen, en betere ruisonderdrukking helpen allemaal in het verbeteren van de herkenning. Maar die onduidelijk geformuleerde vragen is iets anders: daarvoor moet samengewerkt worden met vooral taaltechnologen om te proberen de vraag achter de vraag te achterhalen. We zullen dan ook een verhoogde samenwerking tussen deze twee oorspronkelijk gescheiden onderzoeksgebieden zien en een duidelijk focus op hetgeen iemand bedoeld te zeggen.