
Heb jij het je wel eens afgevraagt? Hoe maakt de spraakherkenner het Groot Diktee der nederlandse Taal? Wij waren bij Telecats in ieder geval heel erg nieuwschierig en hebben het dus gewoon maar even getesd met Arjan van Hessen. Één ding is zeker. Schrijfvouten zoals in dit bericht, zal een computer niet snel maken!
Van spraak naar zinnen
Het is weer december en dat houdt al jaren in: Het Groot Dictee der Nederlandse Taal. Inmiddels niet meer op televisie, maar het radioprogramma “de Taalstaat” besloot om het dictee in ere te herstellen voor de radio. Een paar jaar geleden hadden we met een aantal spraaktechnologie-specialisten al eens onderzocht of wij met een Nederlandse spraakherkenner konden meedoen. En dit jaar hebben we daadwerkelijk 8 zinnen van het Dictee door de spraakherkenner gehaald.
Maar voor we de resultaten echt gaan vergelijken, iets over spraakherkenning. Wat erg lastig is voor de huidige spraakherkenners, is het opschrijven van de herkende spraak in zinnen. Mensen spreken nu eenmaal niet in zinnen en een spraakherkenner doet domweg niets anders dan de binnenkomende audio omzetten in een geschreven representatie. Voor veel doeleinden is dat uitstekend, maar om er grammaticaal correcte Nederlandse zinnen van te maken, is meer nodig.
Woordenlijst
Tenslotte is er de woordenlijst. De herkenner kan 256K woorden herkennen. Dat is best veel maar slechts 20% van de bestaande Nederlandse woorden. Er zijn dus veel (minder frequent gebruikte) woorden die de herkenner niet kan herkennen omdat ze nu eenmaal niet in het woordenlijstje staan. Ook samengestelde woorden zijn een probleem. Een woord als coderoodwaarschuwingen staat nu eenmaal niet in de standaard woordenlijst. Wel staan er de woorden code, rood en waarschuwing in. De herkenning gaat hier dan ook perfect, maar het resultaat is natuurlijk wel “fout”.
Het voordeel van zo’n woordenlijst is dat er in principe alleen maar correct gespelde woorden in staan. Hierdoor zal de herkenner een spelfout die mensen typisch maken nooit maken; de herkenner zal bijvoorbeeld nooit “minuscule” als “miniscule” schrijven, of “debacle” als “debakel”. Dus als het juiste woord herkend wordt, dan bevat het geen spelfouten.
En niet-Nederlandse woorden? Een staande, Friese uiting als ‘It giet oan’, is eigenlijk kansloos als ie er niet als één uiting in staat. Dat staat ie niet en dus wordt deze uiting herkend als “in teheran”.
Tenslotte zijn er de uitspraakfouten waar wij mensen geen probleem mee hebben omdat we begrijpen wat er bedoeld wordt en dus de herkende tekst in die context horen. Voorbeeld in dit dictee is de uiting van Freriks “elfstedentocht in hera willen houden”. Natuurlijk wordt hier bedoeld “Elfstedentocht in ere willen houden”, maar ook na 10x afluisteren blijf je horen dat er (h)era wordt gezegd: en dat herkent de ASR-engine dan ook.
Resultaten
Maar hoe goed deed de herkenner het nu? Hieronder de 8 zinnen met onder iedere correct geschreven zin, de resultaten van de spraakherkenner. We hebben iedere zin zoals beschreven op de website van het programma en voorgelezen door Philip Freriks als een apart bestand door de herkenner gehaald.
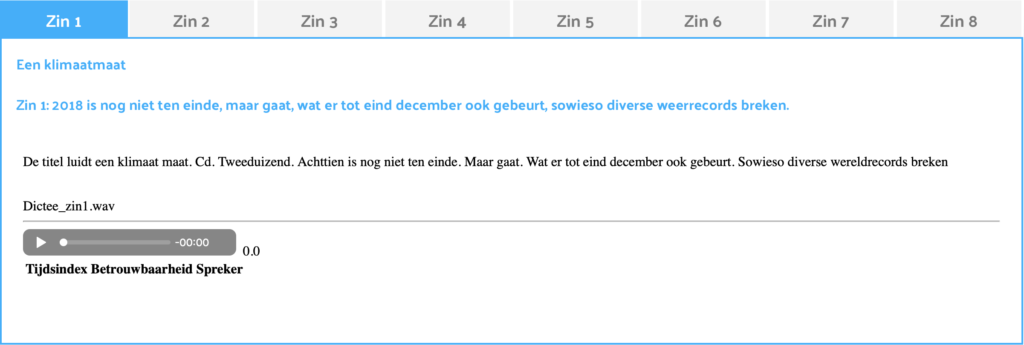
Conclusie
We mogen stellen dat de spraakherkenning best goed is. Hier en daar zien we typische spraakherkenningsartefacten zoals missende hoofdletters, samengestelde woorden die als losse woorden geschreven worden, zinnen die geen zin zijn, missende leestekens, uitspraakfouten die letterlijk herkend worden en ambiguïteit “zon versus zo’n” waar normaalgesproken de context het juiste antwoord geeft.